Implementing a DSL Transpiler in Golang
2024-08-10
It's no secret, I prefer keyboard navigation over clicking through menus. My setup consists of archlinux with Awesome Window Manager, and Neovim.
During the implementation of Nolatask Task Manager, I wanted to add a convenient way to filter tasks by criteria such as due_date, tag, title, etc.
Instead of adding a clunky user interface with many dropdown menus, I decided to make a custom Domain Specific Language (DSL) which would transform into SQL where queries. The benefit of choosing a DSL over generative AI, is that english is ambiguous, while a DSL is unambiguous and predictable (I also value predictability).
High Level Design Decisions
Although a custom DSL is expressive, I wanted to design the DSL to be easy for myself and others to pick up and understand. This is mainly done by designing the grammar of the DSL with two constraints:
- the next possible tokens can always be inferred from the previous ones (except in the cases of strings, symbols, and numbers)
- the different types of tokens must be designed in such a way that each group contains a fairly small set of possibilities
These two constraints make a well crafted autocompletion engine very powerful. At any given time, only a limited set of tokens are possible.
It probably took me several days of diffused thinking to come up with the main concepts of the DSL.
As I started to implement the language, there was one problem:
I don't know much about language parsing and compilers.
Learning Process
In high school, I implemented a calculator for android with string parsing. It supports order of operations, minus signs, and parentheses. Before that, I hadn't touched parsers before. Despite having no formal background in parser or compiler theory, I derive concepts such as that of a token intuitively.
If I wanted to implement my DSL (NTQL --Nolatask Query Language), I would need a much more solid understanding of parsers. Because I wasn't designing a fully blown Turing complete compiler, the main resource I used was Crafting Interpreters. Crafting Interpreters is a highly recommended guide as an introduction to implementing programming languages.
Compiler vs Intepreter
A compiler is a program that translates code into machine code or another programming language, while an interpreter directly executes the code without translating it into another language.
What I am creating here is a compiler. The compiler translates my DSL into SQL WHERE clauses. When a compiler generates code in another programming language, it is called a transpiler.
Implementation
Compilers typically have multiple parts. Each of these parts typically transforms the input into a suitable format for the next part.
Step 1: Scanner
A token is the smallest meaningful unit to a compiler. For example, in the DSL due_date.equals("2024-08-10"), due_date is a token, equals is a token, . is a token, and "2024-08-10" is a token.
A lexeme is the sequence of characters that form a single token.
The scanner turns the source code into lexemes. For example, the string due_date is a lexeme that represents the a token of class 'subject' in my DSL. A lexeme can be represented using a string.
Step 2: Lexer or Tokenizer
The lexer turns classifies lexemes into specific tokens. For example, the lexeme due_date is classified as a token of type subject. Tokens can be represented using a struct, or an object.
type Token struct {
Kind TokenType
Lexeme string
Position int
}
Storing the position of the token in the source code is useful for error reporting, as it allows you to point to the exact location in the source code where an error occurred.
Step 3: Parser
The parser is the meat of the compiler. It takes the tokens produced by the lexer and builds a data structure that represents the structure of the code. This data structure is often called an Abstract Syntax Tree (AST).
I call the parser the meat of the compiler, because it performs the final step of transforming the tokens into a data structure that can be used to generate code. The parser is responsible for understanding the grammar of the language and ensuring that the code is syntactically correct.
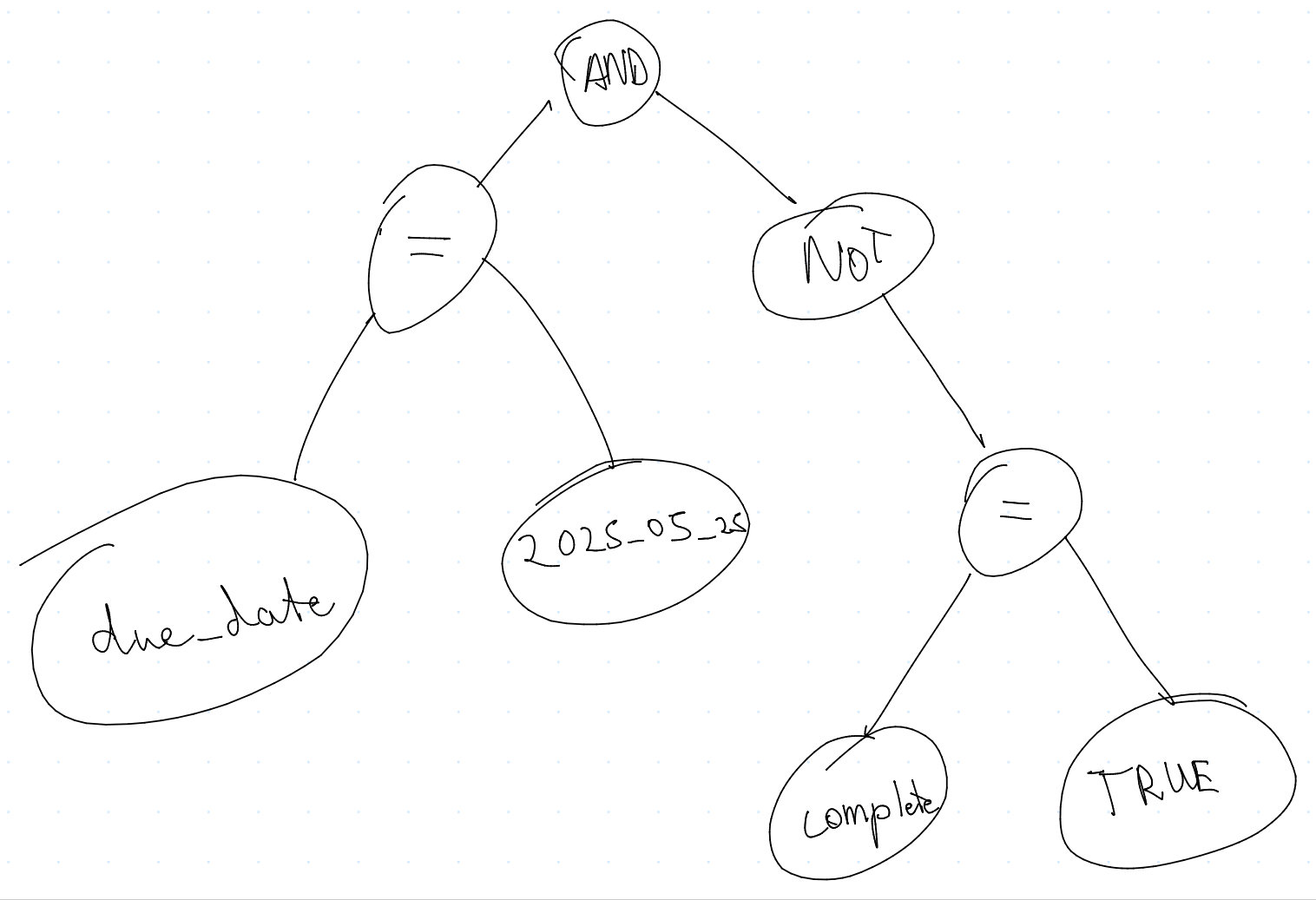 image of an Abstract Syntax Tree (AST)
image of an Abstract Syntax Tree (AST)
Step 4: Code Generation
The final step is to generate code from the AST. In my case, this means generating SQL WHERE clauses from the AST. The code generation walks the AST and generates the corresponding SQL code.
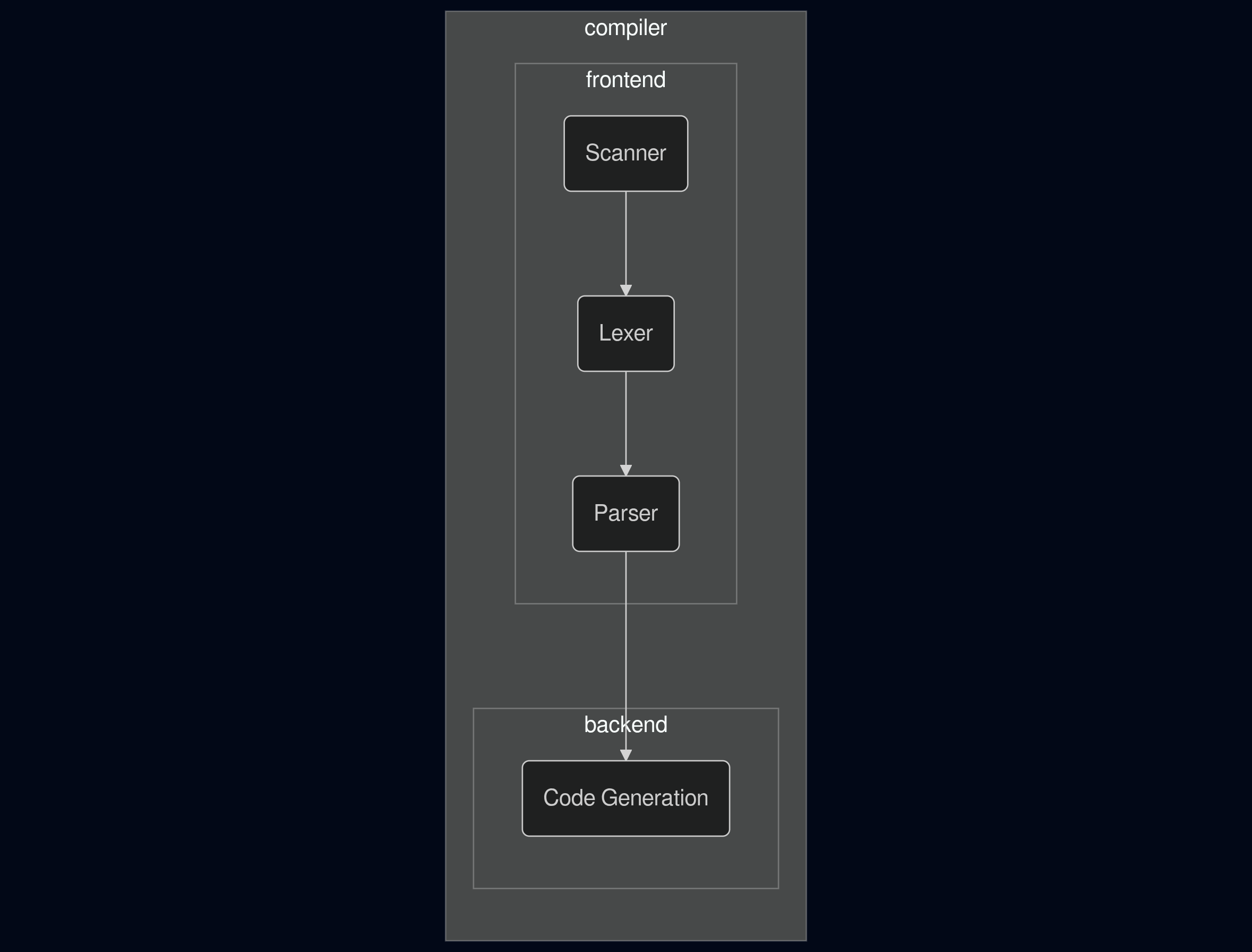 diagram of the steps in a compiler
diagram of the steps in a compiler
All compilers will have a parser and a code generator, but not all compilers will have a scanner or lexer. Some compilers will have a scanner and lexer combined into one step. My parser will have all 4 parts. I hypothesised that the modularity would make implementing the completion engine easier.
Grammar
The grammar of a language defines its structure and rules. It specifies the set of valid statements. Grammar is typically defined using a formal notation such as Backus-Naur Form (BNF) or Extended Backus-Naur Form (EBNF). I will be showing you a BNF grammar for my DSL. expr1 | expr2 means that either expr1 or expr2 is valid.
<query> ::= <expr>
<expr> ::= <or_expr>
<or_expr> ::= <and_expr> | <or_expr> "OR" <and_expr>
<and_expr> ::= <not_expr> | <and_expr> "AND" <not_expr>
<not_expr> ::= "!" <term> | <term>
<term> ::= <func_call> | "(" <expr> ")"
<func_call> ::= <subject> "." <verb> "(" <value_expr> ")"
<value_expr> ::= <value_or>
<value_or> ::= <value_and> | <value_or> "OR" <value_and>
<value_and> ::= <value_not> | <value_and> "AND" <value_not>
<value_not> ::= "!" <value_term> | <value_term>
<value_term> ::= "(" <value_expr> ")" | <value>
<value> ::= <object>
<subject> ::= (subject) // belonging to subjects such as `due_date`, `title`, etc.
<verb> ::= (verb) // belonging to the corresponding verbs such as `equals`, `contains`, etc.
<object> ::= (object) // different data types are allowed based on the subject
This grammar defines the structure of a query in my DSL. The structure allows for complex queries such as these:
due_date.equals("2024-08-10") AND tag.contains("wor")
!tag.equals(hello) AND date.before(2021-01-01) OR title.startswith("bar" OR "c\"\\runch")
!tag.equals(hello) OR date.before(2021-01-01) AND title.startswith(("bar" OR "c\"\\runch") AND "foo")
Implementing the Lexer
The lexer was initially prototyped with a finite state machine (FSM). A FSM is a model that represents a system with finite states and transitions between those states.
The FSM was designed to recognize the different types of tokens in the DSL. This way, the lexer could store information such as the next possible tokens based on the current state. Most lexers don't do so much preprocessing, but I rejected the idea of a simple lexer so that I could implement the completion engine without repeating lots of code. This comes with the cost of making the lexer more complex and tightly coupled with completion engine.
This honestly was probably a bad decision. The tight coupling between the lexer and the completion engine may make independent changes harder in the future. It also adds computational overhead to the lexer, which would be unused during parsing. What I should have done is to implement a simple lexer that only recognizes the tokens and their general types, and then implement a separate completion engine that uses the lexer and a separate FSM to determine the next possible tokens based on the current state. The types used in the lexer would have been identifier, operator, string, number, etc. instead of the more specific types used in the current lexer. The parser and completion engine would then categorize the tokens into the specific types used in the DSL. I probably will refactor the lexer in the future to use the UNIX philosophy of, "do one thing and do it well".
Implementing the Parser
The parser was implemented using a recursive descent parser. A recursive descent parser was chosen because it usually is easier to implement by hand than other types of parsers. The structure of the parser is based on the grammar, which is a huge benefit of using a recursive descent parser.
The following (simplified) go code represents the function used to parse <not_expr> ::= "!" <term> | <term>.
func NotExpr(token) QueryExpr {
if token.kind == TokenBang { // match "!" term
expr := p.Term()
return NewQueryNot(expr)
}
return p.Term() // match term
}
NewQueryNot is a function that creates a struct representing a negation expression, with the argument being the expression to negate.
All the recursive calls to the parser functions build the AST by creating structs that represent the different types of expressions. The parser functions are designed to match the grammar of the DSL, and they return the corresponding AST nodes.
Implementing the Code Generator
Each QueryExpr interface has a ToSQL() method that generates the corresponding SQL WHERE clause. The code generator simply walks the AST and generates the SQL code based on the structure of the AST. Although, there were some edge cases that required special handling, such as handling the tag.equals("foo") case. The tags are stored in a separate table, so the code generator needs to do something like this:
case OperatorEq:
return "tag_id = (SELECT id FROM atomic_tags WHERE title = '" + c.Value + "')"
This code generates a subquery that retrieves the ID of the tag from the atomic_tags table, which is then used in the WHERE clause.
Various structs belong to the QueryExpr interface. QueryBinaryOp handles operators such as "and", "or", and even "xor". QueryUnaryOp handles the "not" operator for now.
// QueryUnaryOp represents a unary operation in a query.
type QueryUnaryOp struct {
Operand QueryExpr
Operator Operator
}
// QueryBinaryOp represents a binary operation in a query.
type QueryBinaryOp struct {
Left QueryExpr
Right QueryExpr
Operator Operator
}
QueryCondition contains the field, operator, and value. Although these operators are those from the method calls such as equals, contains, etc., they are not the same as the SQL operators.
type QueryCondition struct {
Field string `json:"field"`
Operator Operator `json:"operator"`
Value string `json:"value"`
}
Each of these structs implements the ToSQL() method, which generates the corresponding SQL code. It does this by recursively calling the ToSQL() method on the child nodes of the AST.
An important thing to note is that parentheses must be placed correctly in the SQL WHERE clause to ensure the correct order of operations. The parser ensures that the inner expressions are lower in the AST than the outer expressions, so the code generator can simply generate the SQL code in a depth-first manner, while placing parentheses from the bottom up.
Conclusion
Implementing a DSL transpiler in Golang was a challenging but rewarding experience. I learned a lot about parsers, compilers, and the intricacies of language design. The resulting DSL is expressive and easy to use, and it allows for powerful filtering of tasks. I really enjoyed learning so much about compilers. It is definitely a topic I want to explore more in the future. I want to more compiler work in the future, maybe even compiling down to machine code.I could see myself working full time on compilers.
Please tip here