Myers Diff for Tab Management: Part 1
2024-09-16
I am currently developing NolaTabs. NolaTabs is a chrome extension that allows you to version control and organize your tabs. Under the hood, most of the underlying functionality is based on Git's Version Control System (VCS). However, I also wanted it to be user friendly by having an intuitive UI which abstracts most of the complexity (unless you have certain settings turned on).
Why Git?
Git is a tool used to version control files (typically code) in a specific directory. In a very abstract way, it is kind of like a quick save in a game. However, it is vastly more flexible and complex than that. It can also be seen as a ledger for code changes. It was originally created by Linus Torvalds in order to help him to manage Linux. I decided to base the underlying design of NolaTabs on Git for multiple reasons (in their respective order):
- it would give me more in depth familiarity with Git's Version Control System
- the idea of working on one repo/branch/workspace at a time seemed like a great way to encourage me to focus on one task at a time
- VCS seemed like it would map nicely onto tab management, and could create a nice model for how a flexible tab management system would work (better than creating a model from scratch)
- command pallete actions could be easily defined by adding analogous mappings to Git's already existing command line options
Despite the underlying functionality being inspired by Git, there are some salient differences in underlying architecture. In order to better understand the design, we must first delve into some of the basics of how Git works.
Git Commit Graphs
Git stores what are called commits in a graph data structure. A commit is a snapshot of the current working directory, paired with a message that (ideally) summarizes the changes that were made in the current commit. The commit graph details the history of commits made in a git repository. The plan is for NolaTabs to do the same.
One may think that history can be stored in a linked list. However, Git allows for branches. These branches allow for each node to have multiple child commits. It is typical for a Git repository to have a main branch, as well as several feature branches.
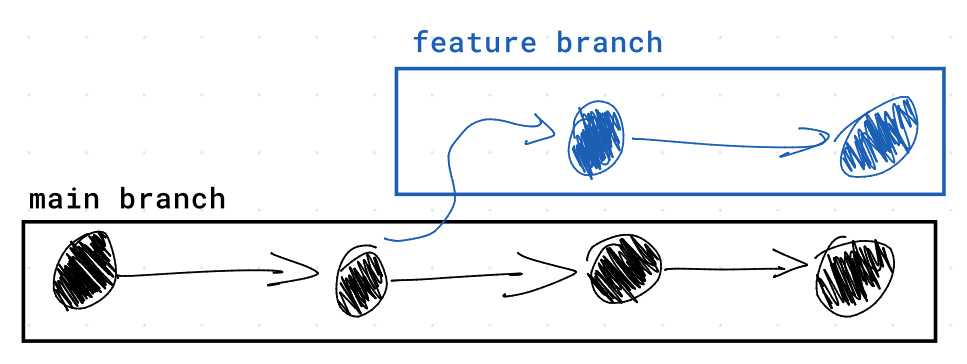
With Git, you are able to "merge" changes from multiple branches. This adds the changes from one branch, into the current branch. Therefore, each node can also have multiple parent commits.
Below, you can find an image of a Git commit graph's data structure, including a merge commit:
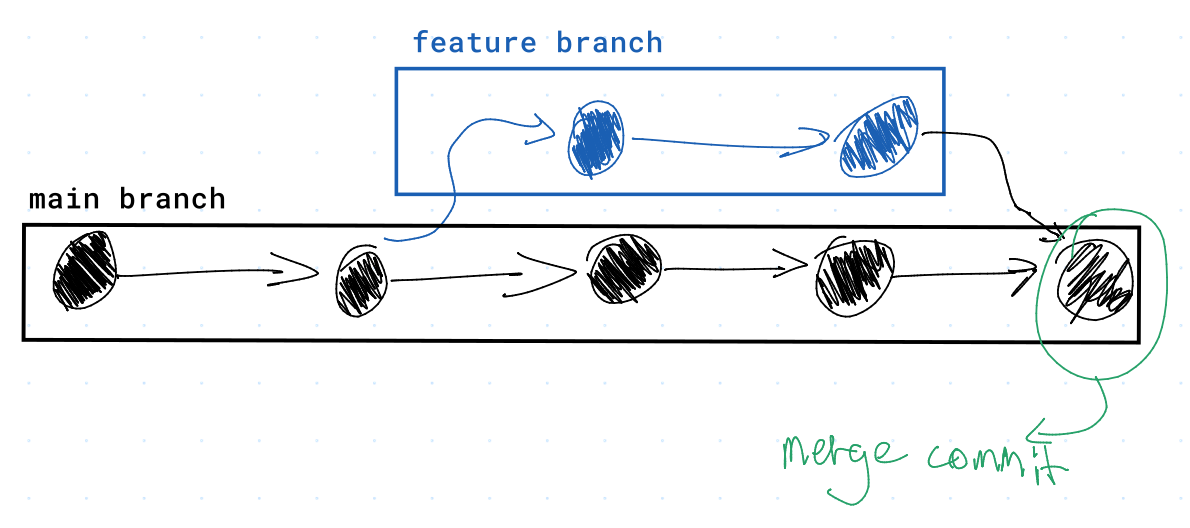
It is important that the graph not have cycles (no path from one vertex to the same vertex). This means that parent, child relationships must go one way (away from the initial commit). This is because we need to be able to traverse commit history is a deterministic manner.
Here is the structure of a commit outlined in TypeScript:
export class Commit {
hash: string;
author: string;
timestamp: Date;
message: string;
diff: CommitDiff;
parents: string[]; // hash of parent commit, empty if no parent (initial commit)
}
The hash is a unique identifier for each commit. This makes them commits easier to share when multiple people work in the same repository. The hash is based on the author information (name, email), message, parent hashes, and the timestamp.
The biggest difference between Git and NolaTabs is that NolaTabs will store diffs instead of snapshots.
Snapshots and diffs
A snapshot is a representation of the state of the current working directory. It is analogous to a picture of your current working state. In Git, this would be the structure of the folders and the contents of different files. However, in a tab manager, this would be the different tabs and their URLs, (as well as their position) in each window.
As you make changes, you may store snapshots one after the other. These snapshots form a history of your changes. In order to derive a future snapshot B from a previous one A, you can re-enact the series of changes made between the two snapshots on the older snapshot A. These changes can be refered to as diffs (short for differences). Each individual change can be referred to as a delta (also short for the Greek word for difference). A delta can be represented by either an addition, or deletion at a specific index.
Inputs
Although Git uses snapshots to store the state of your working directory. I've decided that NolaTabs will not use snapshots, but will use diffs.
Before we defend storing diffs over snapshots, it is important to go over the inputs. The first set of inputs will be the url's and indices of tabs open in the current window. These represent the current state. The input will not be the changes, because we cannot assume the extension will be running to track moves, additions, and deletions of tabs. We can derive these changes using an algorithm which will be discussed later in the article. Each time we commit, we can derive the steps needed to bring about the new state from the last commit.
The second input will be the state from the previous commits we are adding changes on top of.
Why diffs?
One of the main reasons I chose diffs over snapshots is because I was eager to implement the Myers Diffing algorithm. I thought it would be a non-trivial challenge to do so.
Another reason is because this is the way my mental model of Git works. In fact, many older Version Control Systems such as SVN store changes as diffs rather than complete snapshots. I see commits as changes on top of the previous commits, rather than completely new snapshots.
A benefit of using diffs instead of entire snapshots is that there is less data sent to the server. When sending commits to the server, we only need to send the diffs rather than multiple snapshots of the browser state. This makes server and client communication faster, and makes storage more efficient on the server side (theoretically).
Diffs are also smaller to store. Git uses a special type of compression called packfiles. This ensures changes are compressed effiently. The compression is actually based on diffs, so Git doesn't lose much storage space by storing the state of the entire directory in every commit.
Sending diffs between the client and server becomes more secure than snapshots. Only necessary data (changes) are sent between the client and server. This means that one attack on a server request doesn't have to compromise your entire browser's state, but just the most recent changes. It also allows us to implement end to end encryption in such a way that each set of diffs is sent with a different encryption key. This would make it extremely difficult to compromise security as an attacker would need multiple keys and intercept several requests in order to derive just one snapshot.
The cons of storing diffs?
A drawback of diffs is that in order to build a snapshot, you must apply all diffs from previous commits. This can potentially take a lot of time on repositories with many commits. In order to speed this up, we can cache snapshots incrementally. This means storing a snapshots every n commits. This way, we don't have to start from the beginning of the commit graph to create a snapshot. We can simply need to find the last cached snapshot before the commit. Thankfully, commits are immutable. This makes much of the work simpler. Git commits are immutable. Any changes are added to the end of a branch, or to a new branch. This means that the cached snapshots don't have to be recalculated between changes. Caching snapshots potentially makes the speed of switching between commits a non-issue.
An method to increase performance could be to use the diffs and apply their inverses, in order to get previous commits. I plan to avoid doing this for now because snapshots are versatile, and can be stored in custom intervals, and allow snapshots from any index to be built rather efficiently.
A second drawback is that diffs are more complex to store and handle than snapshots. As will be outlined below, there is a complex algorithm to derive the diffs. They must also be applied correctly. Any breakage in the diff chain can cause the wrong snapshot to be built.
Terms
Before delving into the Myers Diffing algorithm, I will define a couple key terms:
- Patching a diff means to apply it (go from one state
Ato another stateF(A)by applying the diffsFtoA) - An edit script is a series of instructions to arrive from one state/snapshot
Ato the nextB.
The LCS Problem
Calculating diffs is all about the Longest Common Subsequence (LCS) problem.
Given two sequences A (length N) and B (length M), the longest common subsequence (LCS) is the longest sequence that appears in both A and B in the same order, but not necessarily contiguously.
Example:
A = "ABCBDAB" B = "BDCABA" One LCS = "BCBA" (length 4)
LCS matters for diffs because the shortest edit script is the one with the longest common subsequence. The smaller the common subsequence you have, the more edits you have to make in order to derive the second string.
If you've taken Data Structures and Algorithms, the LCS problem might sound familiar to you.
If you haven't heard of the LCS algorithm, you may have heard of the similar "edit distance" formula. The algorithm to find the least amount of changes needed to arrive at a different string is known as the "edit distance" formula, or the "Levenshtein Distance" algorithm. However, the edit distance formula allows for substitutions. In the LCS problem, a substitution is represented by a deletion followed by an insertion of a different character.
Enter Myers Diff
Myers Diff is an algorithm that allows us to find the shortest edit script by finding long common subsequence. You can find the origina paper here: original paper. In its most basic form, the time complexity is O(N+M)D, where N and M are the lengths of both input sequences. D is the length of the shortest edit script.
A version of the Myers Diffing algorithm is currently being used as Git's default diffing algorithm. Git allows you to get the diffs between two commits despite git not storing these changes as diffs.
Myers Diff is also used in UNIX's diff command line tool.
In part 2 of this article, I will be explaining the algorithm in detail.
Please tip here